| Крім того, кожному типу складових ставиться певна граматична характеристика. Наприклад, вказівки про тип (розповідне, питальне, окличне), чи є воно особовим чи ні. Якщо речення особове, йому треба приписати вказівки про число та особу. Всі ці вказівки приписуються до нетермінального елементу.
Приклад синтаксичної структури. Алгоритм синтезу. Задачі програм обробки складових. Задачей алгоритму синтеза є перетворення синтаксичної структури описаного вище типу в ланцюг літер, що представляють собою відповідну англійську фразу. При виборі англійського еквіваленту використовуються лише синтаксичні та граматичні характеристики, і не використовуються жодні семантичні відомості або лексичні характеристики. Зручно мати окремі програми для обробки складових кожного типу. Наприклад, програма обробки складових для групи іменника викликається лише тоді, коли повинна бути оброблена група іменника. Всі ПОС (програми обробки складових) повинні бути написані як рекурсивні програми, оскільки одна складова може міститися в іншій, і кожній ПОС необхідно вміти викликати інші ПОС. Зміна порядку слів здійснюється за допомогою зміни порядку адрес у відповідному елементі. Вибір англійського еквіваленту російського слова і надання йому потрібної форми здійснюється в останній момент, коли є вся інформація, необхідна для даної ПОС. Приклади ПОС. ПОС для групи іменника. Перед групою іменника вставляється англійський прийменник, який визначається відмінком і вказівкою про синтаксичну функцію групи, наприклад, перед групою іменника вставляється прийменник of в тому випадку, коли вона має вказівку про родовий відмінок і є неузгодженим означенням в групі іменника. Узгоджені означення, які містять слова, залежні від прикметника або дієприкметника, і стоять після них, розміщуються в кінці групи, при цьому ставляться відповідні коми. Результат аналізу: 
Результат синтезу: primary signs of speech signals, chosen by system, ПОС для групи дієслова. В групу особового дієслова вставляються допоміжні дієслова і заперечна частка not, коли це необхідно. Результат аналізу: Результат синтезу: 
are insignificantly changed Ця група дієслова має такі граматичні характеристики: 3-я особа, множина, теперішній час, пасив. Тому ПОС для групи дієслова вставляє are і передає управління ПОС для прикметника. Ця ПОС видасть англійський прикметник з суфіксом –ly. Пропонуєма модель синтаксичної структури і описаний алгоритм є задовільними. Вони мають ту перевагу, що переклад може здійснюватись і при неповному алгоритмі. “Мультістор” – система кореляційного аналізу для англійської мови. Е. фон Глаузерсфельд Дана робота італійського дослідника Е. фон Глаузерсфельд виконана в рамках так званого кореляційного підходу до автоматичного перекладу, який розроблявся з кінця 50-х років під керівництвом Сільвіо Чеккато в Міланському університеті. Специфіку цього підходу складає його семантичне спрямування: при автоматичному перекладі необхідно з самого початку добувати з тексту і фіксувати певним чином його смисл, який потім повинен виражатися засобами вихідної мови. В якості основного засобу зображення смислових зв’язків між словами пропонується кореляція, або зв’язок. Кореляційний синтаксис відрізняється від традиційного головним чином тим, що вся увага в ньому зосереджується на окремих словах, а не на класах слів. В кореляційному синтаксисі слову приписується набір індексів, кожний з яких відображає здатність даного слова утворювати певну кореляцію з іншим словом, що має той самий індекс кореляції. Це дозволяє відразу ж відкинути багато комбінацій слів і словосполучень, які можуть бути правильними з точки зору граматики, але безглузді з точки зору семантики. Метод кореляційного аналізу використовує багато різних “синтакисчних функцій”. Як наслідок цього синтаксичних індексів при кожному слові більше, ніж ознак традиційної класифікації. При такому збільшенні вихідних даних кількість елементарних операцій, потрібних для синтаксичного аналізу, дуже зростає. Наприклад, нехай деякому слову приписано 50 кореляційних індексів. Для того, щоб скласти кореляцію, машина повинна порівняти кожний індекс першого слова з кожним індексом другого, тобто виконати 2500 порівнянь. Якщо тепер пара слів, вже пов’язаних в кореляцію, буде рекласифікована, тобто отримає нові можливості вступати в кореляції, то їй буде приписана нова серія з 50 індексів. Така пара потребує в свою чергу 2500 порівнянь з наступним словом або такою ж парою. Для аналізу речення середньої довжини при такому підході знадобилось би сотні тисяч порівнянь кореляційних індексів. Проте попередні дослідження показали, що можна досягти значного зменшення кількості порівнянь, якщо враховувати, наприклад, порядок слів в кореляціях. Намагання зменшити кількість операцій і породило систему “Мультістор”. Кореляційний аналіз. Корелятор – мовний вираз деякого відношення. Слова будь-якої мови можна розподілити на два типи: 1) слова, що позначають певні смислові відношення між об’єктами та 2) слова, що позначають самі ці об’єкти. Слова першого типу називають єкспліцитними кореляторами, а слова другого типу – простими словами або кореляндами. Коли відношення не має для свого виразу спеціального слова, говорять про імпліцитні корелятори. Кореляція з імпліцитним корелятором складається з двох слів. Наприклад, “дівчинка співає” – тут смислові відношення виражені за допомогою морфологічних характеристик , а саме, особова форма дієслова показує, що дія, позначена дієсловом, виконується в даному випадку дівчінкою. Кореляція з експліцитним корелятором повинна містити щонайменше три слова. Наприклад, в словосполученні “червоний та чорний” експліцитним корелятором виступає сполучник та. Перше та третє слово називаються корелятами.
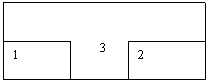
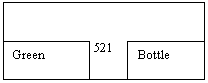
Для зображення кореляцій використовується графічне представлення. 1 – місце першого корелята, 2 – місце другого корелята, 3 – місце корелятора. Кореляція “green bottle”.
521 – індекс того імпліцитного корелятора, якому в традиційній граматиці відповідає синтаксична функція “прикметник, що є означенням іменника”. В кореляціях дуже важливим є порядок слів, тому недостатньо в словарних статтях вказувати лише індекси кореляцій, в яких слово може приймати участь, необхідно вказувати також порядкове місце слова в кореляції. Так, словарні статті слів bottle та green повинні містити таку інформацію: | Корелят | Ic – індекс кореляції | CF – значення кореляційної функції | | Bottle | Ic 521 | CF2 | | Green | Ic 521 | CF1 |
При експліцитному корелятору графічне представлення буде таке: Фрагмент словника для цих двох словосполучень буде мати вигляд: | Корелят | Ic – індекс кореляції | CF – значення кореляційної функції | | Bottle | Ic 521 | CF2 | | Green | Ic 521 Ic 014 Ic 014 | CF1 CF1 CF2 | | And | Ic 014 | CF3 | | Blue | Ic 521 Ic 014 Ic 014 | CF1 CF1 CF2 |
|